The short answer
In Unix-like operating systems such as Linux and macOS, you can scan patterns and process the output of commands using the awk command as follows:
Where:
- <command> is the command whose output you want to process or filter.
- <pattern> is a text string or a regex pattern used to filter the output of the specified command.
- <action> is the action to perform on the lines matching the specified pattern.
Alternatively, you can also pass one or more file paths as arguments:
For example, the following command will print to the standard output all the lines of the server.log file containing the error string:
And the following command will print to the standard output all the lines of the server.log file starting with the 2024-05 string:
Splitting the output into columns
By default, the awk command splits every line of its input into multiple columns, using the space character as a delimiter.
To print one or more specific columns instead of the entire line, you can use the following syntax:
Where:
- $<column>[,$<column>] is a list of comma-separated column numbers prefixed with a dollar sign ($).
For example, this command will only print the first column of the output generated by the ps command:
And this command will print the first and fourth columns of the output generated by the ps command:
Note that you can quickly reference the last column using the pre-defined $NF variable as follows:
Using custom delimiters
To split the output of commands into columns based a specific delimiter instead of the default space character, you can use the -F flag as follows:
Alternatively, you can specify multiple delimiters at once by encapsulating them in square brackets as follows:
For example, considering the following data.csv file:
The following command will use the , character to split each line of the data.csv file into separate columns and only output the third column:
Summing up and counting columns
Counting the occurrences of a pattern
To count the occurrences of a specified pattern with awk, you can increment a variable using the ++ operator as follows:
For example, considering the following server.log file:
This command will increment the count variable every time the "ERROR" string is found in the server.log file:
Summing up the data of columns
To add up the values of a column and print their sum with awk, you can use the following syntax:
Where:
-
<variable> is the name of the variable the sum of the specified column will be accumulated in.
-
<column> is the column number to add up.
-
END is used to specify a command to execute once all the lines are processed.
For example, considering the following data.csv file:
This command will print the sum of the values of the second column:
Where:
-
cat data.csv is used to output the file's content.
-
tail -n +2 is used to remove the first line of the output.
-
awk -F ',' is used to split each line of the output into columns using , as a separator.
-
{sum += $2} is used to add the value of the second column to the sum variable.
-
END {print sum} is used to print the sum variable.
Manipulating text
Extracting a substring
To extract a substring from a line with awk, you can combine the print and substr functions as follows:
Where:
-
<column> is the column number of the string you want to extract a substring from. Note that the full input string can be accessed through the column number 0.
-
<start> is a number representing the starting position within the specified string.
-
<length> is a number representing the length of the substring.
For example, this command will take as input the entire "Hello World" string and print 5 characters starting at position 7:
And this command will take as input the second column and print 5 characters starting at position 0:
Replacing the occurrences of a string or pattern
To replace all the occurrences of a string or pattern with awk, you can use the gsub function as follows:
Where:
-
<pattern> is the string or pattern you want to replace.
-
<string> is the string you want to replace the matched pattern with.
For example, this command will replace all the occurrences of the letter l with x:
Easily retrieve this command using the Warp’s AI Command Suggestions
If you’re using Warp as your terminal, you can easily retrieve this command using the Warp AI Command Suggestions feature:
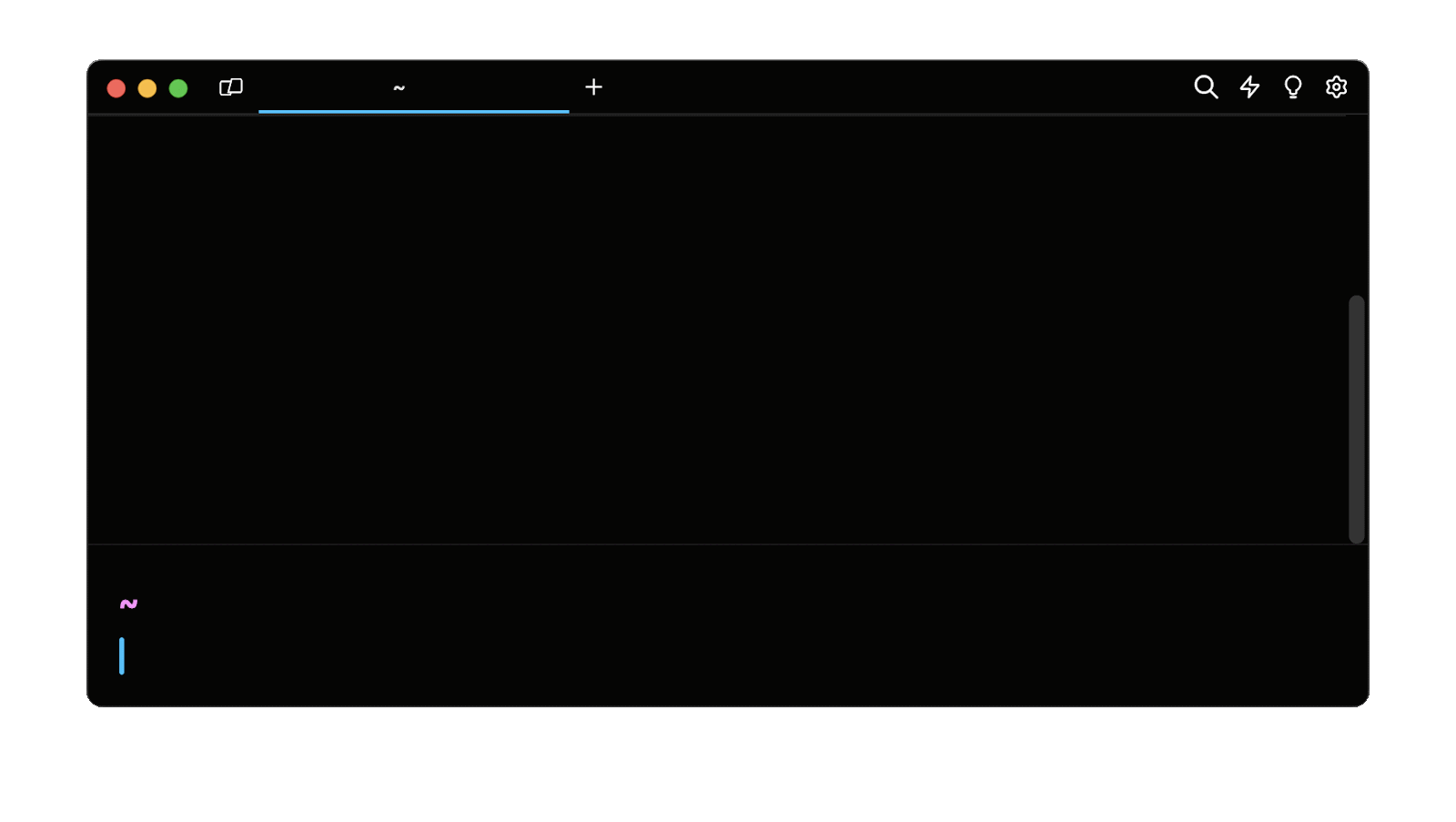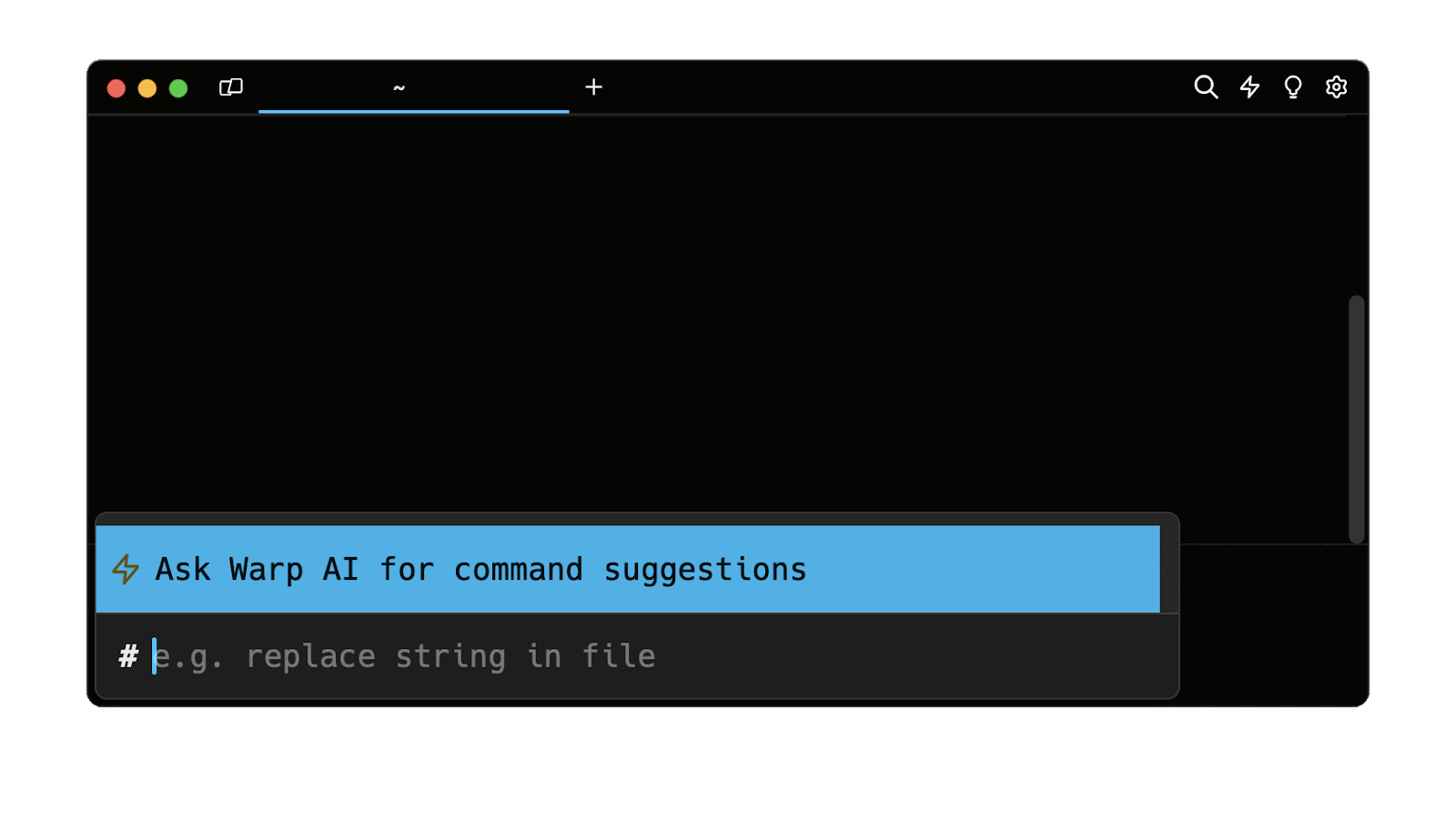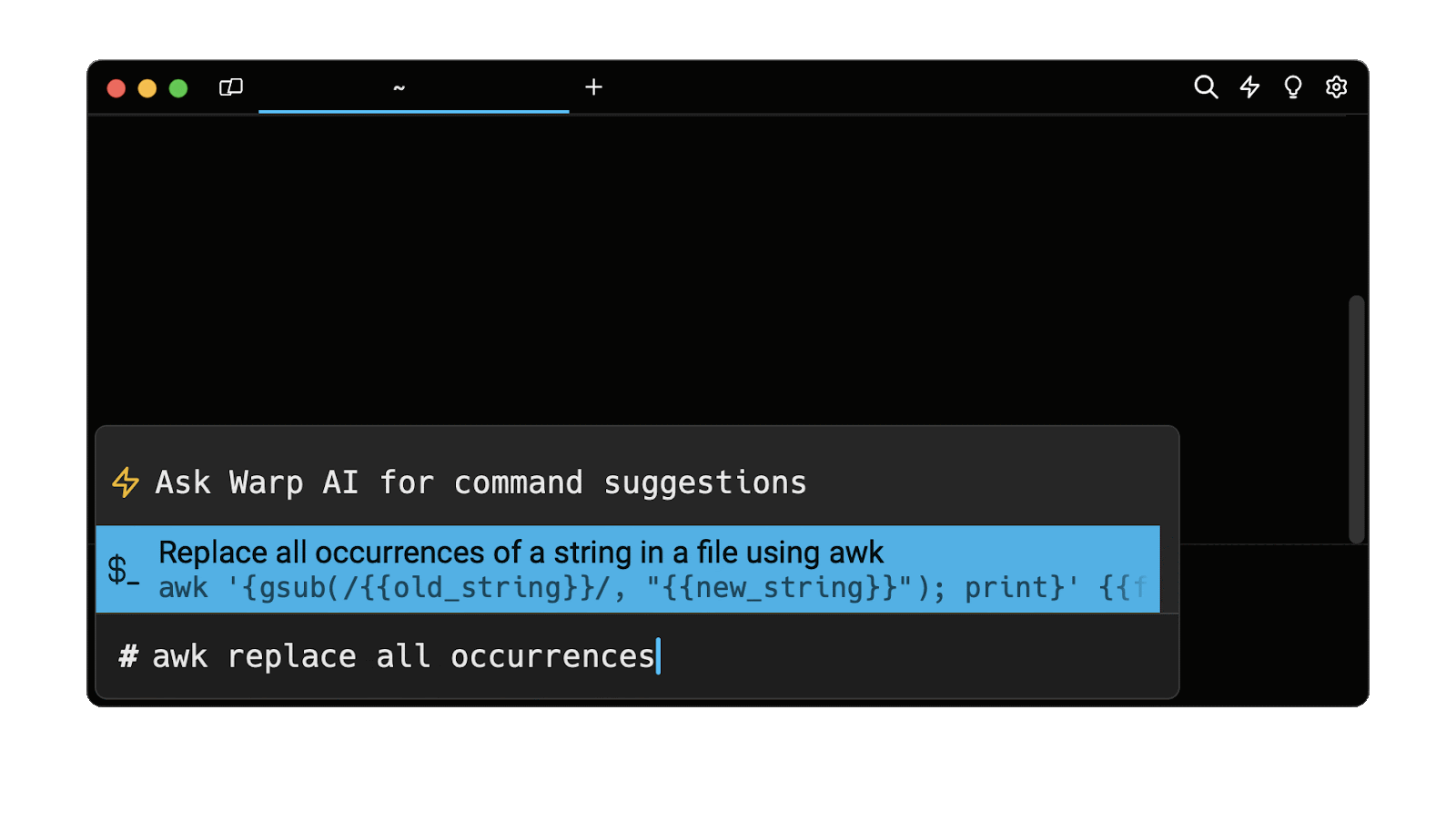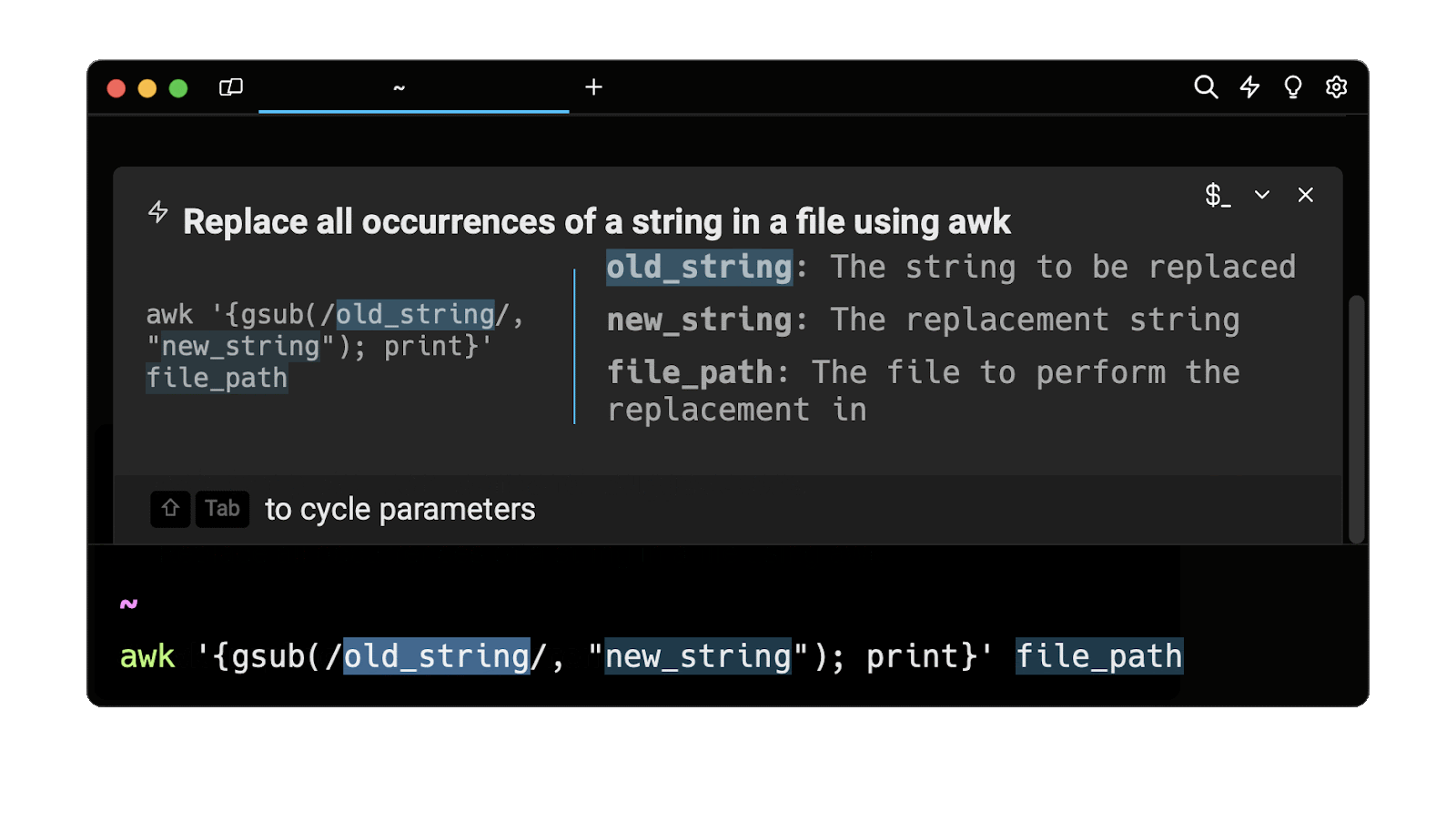
Entering awk replace all occurrences into the AI Command Suggestions will prompt a awk command that can then be quickly inserted into your shell by doing CMD+ENTER.
Conditional statements
To execute an action based on the evaluation of a condition with awk, you can use the following syntax:
For example, let's consider the following students.txt file:
This command will check if the value of the second column is greater or equal to 40 and print the first column with “Passed” if true, or “Failed” otherwise:
Written by
Emmanuel Oyibo
Filed Under
Related Articles
List Open Ports in Linux
Learn how to output the list of open TCP and UDP ports in Linux, as well as their IP addresses and ports using the netstat command.

Count Files in Linux
Learn how to count files and folders contained in directories and subdirectories in Linux using the ls, find, and wc commands.
How to Check the Size of Folders in Linux
Learn how to output the size of directories and subdirectories in a human-readable format in Linux and macOS using the du command.
Linux Chmod Command
Understand how to use chmod to change the permissions of files and directories. See examples with various chmod options.
POST JSON Data With Curl
How to send valid HTTP POST requests with JSON data payloads using the curl command and how to avoid common syntax pitfalls. Also, how to solve the HTTP 405 error code.

Create Groups In Linux
Learn how to manually and automatically create and list groups in Linux.
Switch Users In Linux
Learn how to switch between users, log in as another user, and execute commands as another user in Linux.
Remover Users in Linux
Learn how to remove local and remote user accounts and associated groups and files in Linux using the userdel and deluser commands.
Delete Files In Linux
Learn how to selectively delete files in Linux based on patterns and properties using the rm command.
Find Files In Linux
Learn how to find and filter files in Linux by owner, size, date, type and content using the find command.
Copy Files In Linux
Learn how to safely and recursively copy one or more files locally and remotely in Linux using the cp and scp command.
Create Files In Linux
Learn how to create regular files in Linux using command line interface commands like touch, echo, cat, printf, and in-terminal text editors like Vim.
